Joshua TothJest’s ‘beforeEach’ may not be running the way you think it does…For the last few years I’ve been a pretty heavy user of Jest, I use it as my test runner across both my FE and BE stacks. While I’m a…Mar 17, 2021Mar 17, 2021
Joshua TothBuilding a completely serverless, secure, VOD e2e platform in AWS in 5 days.1 day of planning and 4 days of coding.Jan 30, 2021Jan 30, 2021
Joshua TothHow to fuck up your brand new project right away.For the last few years I’ve been a part of several brand new and phase one projects. No matter the size of the team or business this…Feb 25, 20201Feb 25, 20201
Joshua TothAWS Route 53 redirecting to an external https domain.I recently migrated my personal site from one domain to the other, to ensure I still received traffic from the original domain I…Jul 1, 20193Jul 1, 20193
Joshua TothinCrowdboticsBuilding A Serverless IoT FinTech App with AWS and NodeJSBuilding an AWS native, Node.js, serverless, event-driven system to back up an IOT device capable of real time messaging and events.Feb 10, 20192Feb 10, 20192
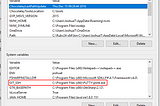
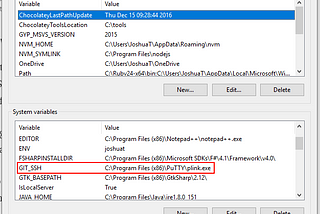
Joshua TothWindows: Use PuTTY for git SSH (Or any SSH agent)Something that seems to come up a lot when using git on windows is wanting to use an SSH client to manage keys. When you want to use…Mar 5, 2018Mar 5, 2018
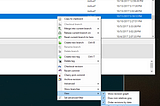
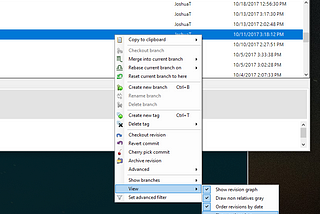
Joshua TothGit extensions: Show commit date instead of author dateGit extensions has an annoying default setting of showing when a commit was authored, rather than when it was committed to the repository…Mar 4, 2018Mar 4, 2018
Joshua TothBreaking apart your Monolith: 4 Issues with scheduled deploymentsJoshua TothFeb 8, 2018Feb 8, 2018